파이썬 html 파싱 은 다른 어떤 언어보다도 쉽고 빠르게 원하는 데이터만 추출할수가 있습니다. 이런 방법을 응용하면 예를들어 커뮤니티에 있는 사진파일들을 전부 다운받기도 가능하고 외부 게시판의 게시판의 글 목록과 링크를 긁어오는 것도 쉽게 할 수 있죠. 파이썬으로 웹페이지에서 원하는 정보를 모으고 엑셀로 저장하면 게시판의 import 기능을 활용해 게시글 목록을 쉽게 추가할수도 있습니다. 이런 좋은 방법을 예제로 테스트해보고 알아보겠습니다.
목차
파이썬 html 읽고 데이터 엑셀로 저장하기
필요 라이브러리
윈도우에 파이썬을 설치하셨다면 cmd를 한번 열어주세요. 바탕화면 아무데나 마우스 포인터를 가져다 놓고 “shift를 누른채로 마우스 우클릭을 하시면 여기서 명령 창 열기”가 나올거에요 아니면 실행창에 cmd를 치셔도 됩니다.
커맨드창 왜 켰냐구요? 파이썬 html 파싱 하기 위해 필요한 라이브러리가 있어요.
pip install beautifulsoup4
pip install xlrd
pip install openpyxl
pip install pandas
위의 명령어를 한줄씩 복사붙여넣기 후 엔터를 쳐주세요. 네개의 라이브러리를 다 설치하셨으면 아래로 내려가셔도 됩니다.
openpyxl은 지금은 쓰지 않겠지만 미리 설치해 두면 다음에 excel파일을 다룰때 설치하는 번거로움이 없을 것 같아 미리 설치 하겠습니다.
예제1 fifa랭킹 가져오기
예제로 fifa랭킹을 가져와 볼게요.
피파랭킹이 있는 사이트의 주소는: https://www.fifa.com/fifa-world-ranking/ranking-table/men/
크롬개발자모드(f12)로 html파일 파악하기
크롬의 경우 위의 사이트에 들어가서 f12를 눌러서 개발자 모드를 켜주세요.
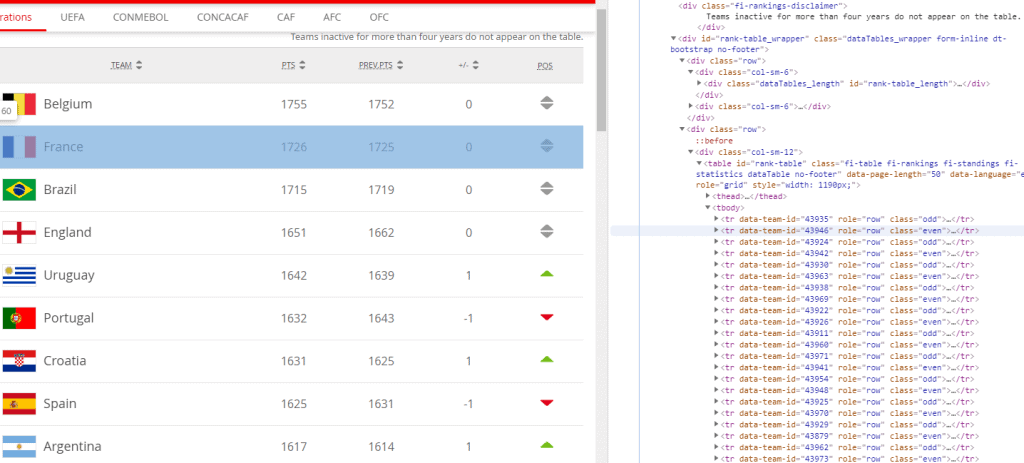
코드에 마우스를 가져가면 코드와 일치하는 화면이 위와 같이 드래그된 것 처럼 파랗게 표시가 됩니다. ▶에는 한 태그 내에 속한 하위 태그들이 들어있어요. 그러니까 코드 접어놓기 같은거죠. ▶ 를 누르면 ▼ 로 바뀌고 코드가 펼쳐집니다. 몇 번 거쳐서 코드를 펼치면서 파랗게 선택된 부분의 태그를 찾아가다 보면 태그가 어떻게 분류되었는지 확인이 가능해요.
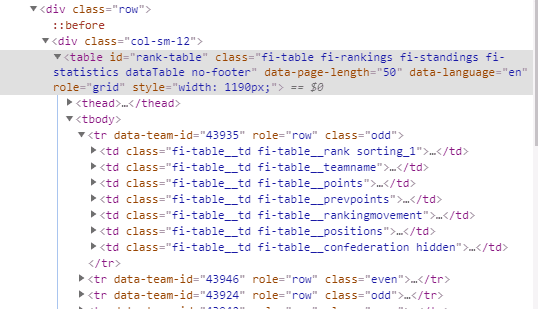
결국 중요하게 봐야될 것을 찾았어요. id가 rank-table인 table요소 밑에 tbody태그가 있었고 그 밑으로 tr에는 랭킹 별 국가와 점수 등등이 담겨있는 줄 tr(table row)이 되겠네요. 각 요소는 td(table data)로 표시되어 있겠구요.
제가 저 중에 관심있는 값은 fi-table__rank과 fi-table__teamname그리고 fi-table__points에요. 이곳에 랭킹 과 국가 이름, 그리고 피파점수가 각각 담겨 있어요.
3가지 요소 출력해 보기
저 세 요소만 파이썬으로 프린트 해보겠습니다.
import pandas as pd
import requests
from bs4 import BeautifulSoup
fifa_rank = “https://www.fifa.com/fifa-world-ranking/ranking-table/men/”
fifa_rank_html = requests.get(fifa_rank)
fifa_rank_html_list = BeautifulSoup(fifa_rank_html.content ,”html.parser”,from_encoding=’utf=8′)
fifa_rank_list = fifa_rank_html_list.select(‘#rank-table >tbody>tr’)
for obj in fifa_rank_list :
print(obj.find(‘td’, {‘class’: ‘fi-table__rank’}).text,’위 : ‘, obj.find(‘span’, {‘class’: ‘fi-t__nText’}).text,’ ‘, obj.find(‘td’, {‘class’: ‘fi-table__points’}).text +’점’)
약간의 설명을 드리자면
fifa_rank에는 가져올 html의 주소
get요청으로 html코드를 받으면 fifa_rank_html에 전부 담기게 됩니다.
BeautifulSoup 의 첫 인자엔 받아온 html소스 데이터 그리고 두 번째엔 파서로 “html.parser”를 사용하겠다 세번째로 인코딩은 utf-8로 하겠다고 인자로 넣어 알려줍니다.
select 를 사용해서 rank-table id를 가진 것 안에 있는 tbody 하위 tr 항목들을 list로 쓰겠음을 표시합니다.
#rank-table >tbody>tr 이렇게 쓰는걸 어떻게 아냐 하실수도 있는데 쉽게 알 방법이 있습니다.
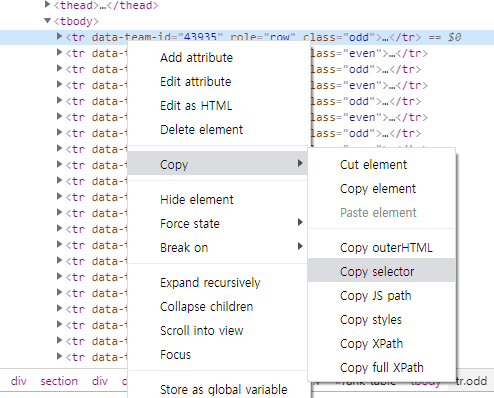
tr 태그 위에서 마우스 우클릭을 해보세요 Copy -> Copy selector라고 써진게 보이시죠?
rank-table > tbody > tr:nth-child(1) 이 곳에 복사 붙여넣기를 했더니 이렇게 나오네요.
그런데 tr에 nth-child(1)이라 써진거는 첫번째 요소임을 의미하는 것이니 우리는 모든 tr요소를 확인해야 하므로 저 부분을 지워버리면 되겠죠? 그럼 복사 붙여넣기만 하면 그대로 쓸 수 있게 되는거에요.
다시 코드로 돌아와서 for문이 돌면서 tr인 fifa_rank_list 요소들을 전부 체크하게 되고
obj.find(‘td’, {‘class’: ‘fi-table__rank’}).text : obj 중에서 td요소를 찾고 class가 fi-table__rank 인 경우 해당 text요소를 얻어옵니다.

팀이름의 경우 상당히 안쪽에 있습니다. 그래서 span 요소 중 class 이름이 일치하는지 확인하는 과정이 바로 아래의 설명입니다.
obj.find(‘span’, {‘class’: ‘fi-t__nText’}).text : span 요소 중 class 이름이 fi-t__nText인 것의 text요소를 가져오기
obj.find(‘td’, {‘class’: ‘fi-table__points’}).text : rank요소 처럼 바로 td하위에 있는 text가져오기
파이썬으로 몇 줄 안되는 짧은 코드로 랭킹, 팀이름, 점수 만 뽑아내 출력을 했습니다.
엑셀파일로 저장하기
이제 이 결과를 csv로 저장해 보겠습니다.
data=[]
를 for문 위에 써주시고
for문의 print문 아래에 data.append([obj.find(‘td’, {‘class’: ‘fi-table__rank’}).text,obj.find(‘span’, {‘class’: ‘fi-t__nText’}).text,obj.find(‘td’, {‘class’: ‘fi-table__points’}).text])
를 써주세요.
그리고 for문이 끝난 이후인 그 아래에
df = pd.DataFrame(data, columns=[‘rank’, ‘team’, ‘point’])
df.to_csv(‘fifa_ranking.csv’,index=False, encoding=”utf-8″)
를 써서 데이터를 저장하면 끝납니다.
약간의 설명
data=[] : data라는 list를 만들기
리스트인 data에 append를 이용해서 리스트의 항목을 추가
DataFrame을 이용해 열의 항목으로 rank, team, point 쓰기
df.to_csv를 통해 fifa_ranking.csv 파일 이름으로 저장
index=false로 해서 csv파일에 index가 추가로 써지는것을 막기
결과
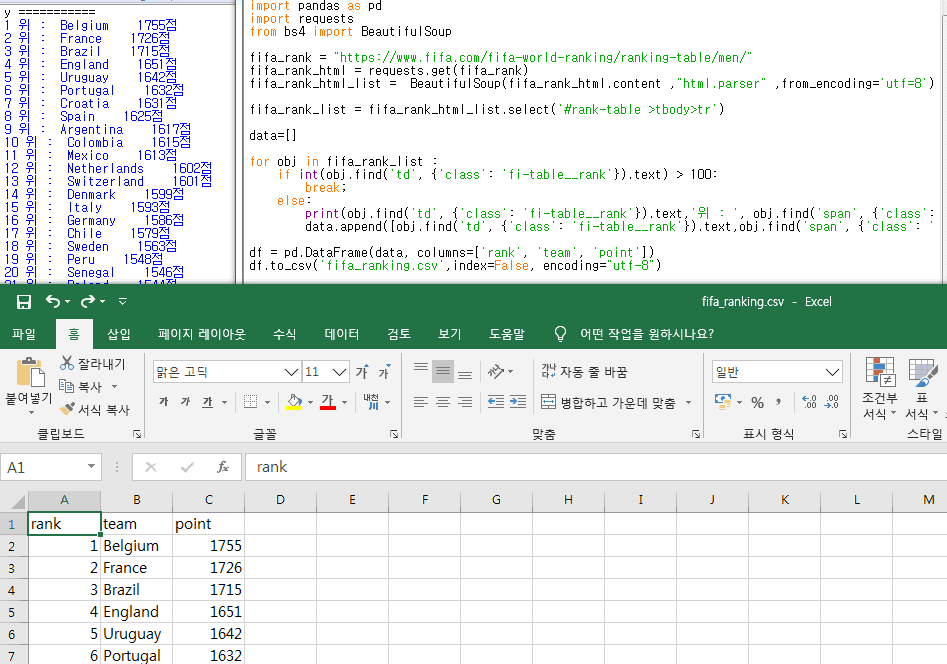
100위 까지만 출력하고 저장하도록 if문 하나만 추가하고 돌려본 결과입니다.
다들 아시겠지만 혹시나 해서 말씀드리는데 python 코딩시 주의할점 for문이나 if문 같이 분기가 나뉘는 경우는 아래에서 tab으로 띄우셔야 합니다. 복사붙여넣기 해서 안되는 경우 대부분 tab이 적용이 안돼서 그렇습니다. for문이나 if문을 사용하실때는 아래에 있는 빈칸을 지우시고 tab을 새로 넣으시는게 좋을거에요.
예제2 cpu benchmark 파싱하기
cpu 벤치마크 순위도 저장해봐요.
cpu 벤치마크 점수보는 사이트: https://www.cpu-monkey.com/en/cpu_benchmark-passmark_cpu_mark-4

여기도 마찬가지로 코드를 봤는데 tr이 다른데는 전혀 쓰이지 않고 tbody안에만 있더라구요. 그래서 그냥 select에 tr만 써서 tr요소만 전부 가져와서 하려고 기존 코드를 아주 조금만 바꿨어요.
조금 다른점은 a태그 안에 있는 값을 읽는 것과 div안에 있는 값을 읽게 바뀐것 밖에 없죠.
import pandas as pd
import requests
from bs4 import BeautifulSoup
cpu_rank = “https://www.cpu-monkey.com/en/cpu_benchmark-passmark_cpu_mark-4”
cpu_rank_html = requests.get(cpu_rank)
cpu_rank_html_list = BeautifulSoup(cpu_rank_html.content ,”html.parser” ,from_encoding=’utf=8′)
cpu_rank_list = cpu_rank_html_list.select(‘tr’)
data=[]
for obj in cpu_rank_list :
print(obj.find(‘a’, {‘class’: ‘black’}).string,’ : ‘, obj.find(‘div’, {‘class’: benchmarkbar’}).string)
data.append([ obj.find(‘a’, {‘class’: ‘black’}).string, obj.find(‘div’, {‘class’: benchmarkbar’}).string ])
df = pd.DataFrame(data, columns=[‘name’, ‘score’])
df.to_csv(‘cpu_ranking.csv’, encoding=”utf-8″)
되겠지 하고 돌려봤더니…

이런 에러가 나는거에요. 뭔가 했더니 object가 string요소를 가지고 있지 않은데 값을 달라고 하니까 에러가 난거에요.
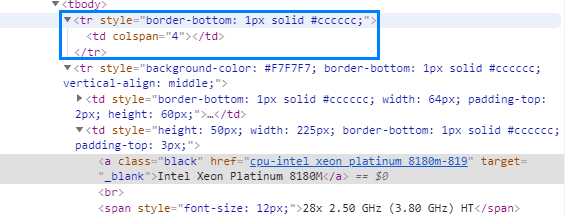
다시 코드를 보니 첫 번째 tr에 안에 내용이 아무것도 없더라구요.
그래서 두번째부터 tr값의 데이터를 사용하면 되겠다 싶어서 코드를 약간 수정했습니다.
data=[]
skiptrcnt=1
for obj in cpu_rank_list :
if skiptrcnt<= 1:
skiptrcnt=skiptrcnt+1
continue
else:
print(obj.find(‘a’, {‘class’: ‘black’}).string,’ : ‘, obj.find(‘div’, {‘class’: ‘benchmarkbar’}).string)
data.append([ obj.find(‘a’, {‘class’: ‘black’}).string, obj.find(‘div’, {‘class’: ‘benchmarkbar’}).string ])
df = pd.DataFrame(data, columns=[‘name’, ‘score’])
df.to_csv(‘cpu_ranking.csv’, encoding=”utf-8″)
data아래 부분만 몇 줄 추가했어요.
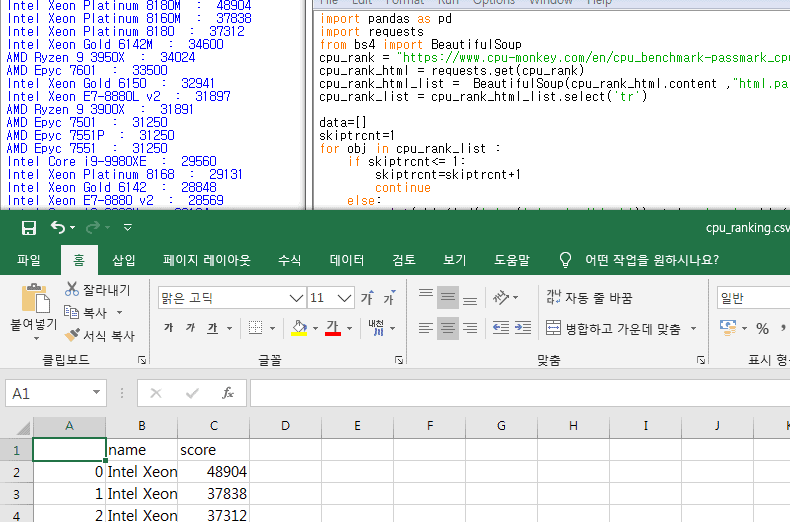
돌려보니 프린트도 제대로 되고 결과도 제대로 저장이 되네요.
이곳의 결과는
fifa 랭킹: https://lsrank.com/ranking/fifa-ranking/
cpu 벤치마크 순위 : https://lsrank.com/ranking/cpu-benchmark/
파이썬 html 파싱 을 이용해 글 쓰는데도 이용하고 아주 유용하네요.